Matching VM Acceleration
Describes how to accelerate regular expression matching.
Regular Expression Matching
Regular expression matching is done many times during fuzzing, so it is important to accelerate it. Although many methods to accelerate matching have been studied, it is not easy to use them directly for recheck fuzzing, because we want to determine how long matching takes, so we have to accelerate it and mimic the behavior of existing matching implementations at the same time.
A typical method to speed up regular expression matching is to construct a deterministic finite state automaton (DFA). In some cases, instead of actually constructing a DFA, we can execute the states of the NFA in parallel and cache the same set of states. However, it is difficult to mimic the priority of backtracking because these methods hide the structure of backtracking, and they cannot interpret backreferences correctly because they rely on finite state automata.
Therefore, we decided to use selective memoization by Davis et al. in recheck.
Acceleration by Memoization
The key idea in Davis et al.'s work is the following
When matching by NFA backtracking, if it memoizes the results from the confluence of branches in the transition diagram, it will reach a certain state at a certain position in the input string at most once.
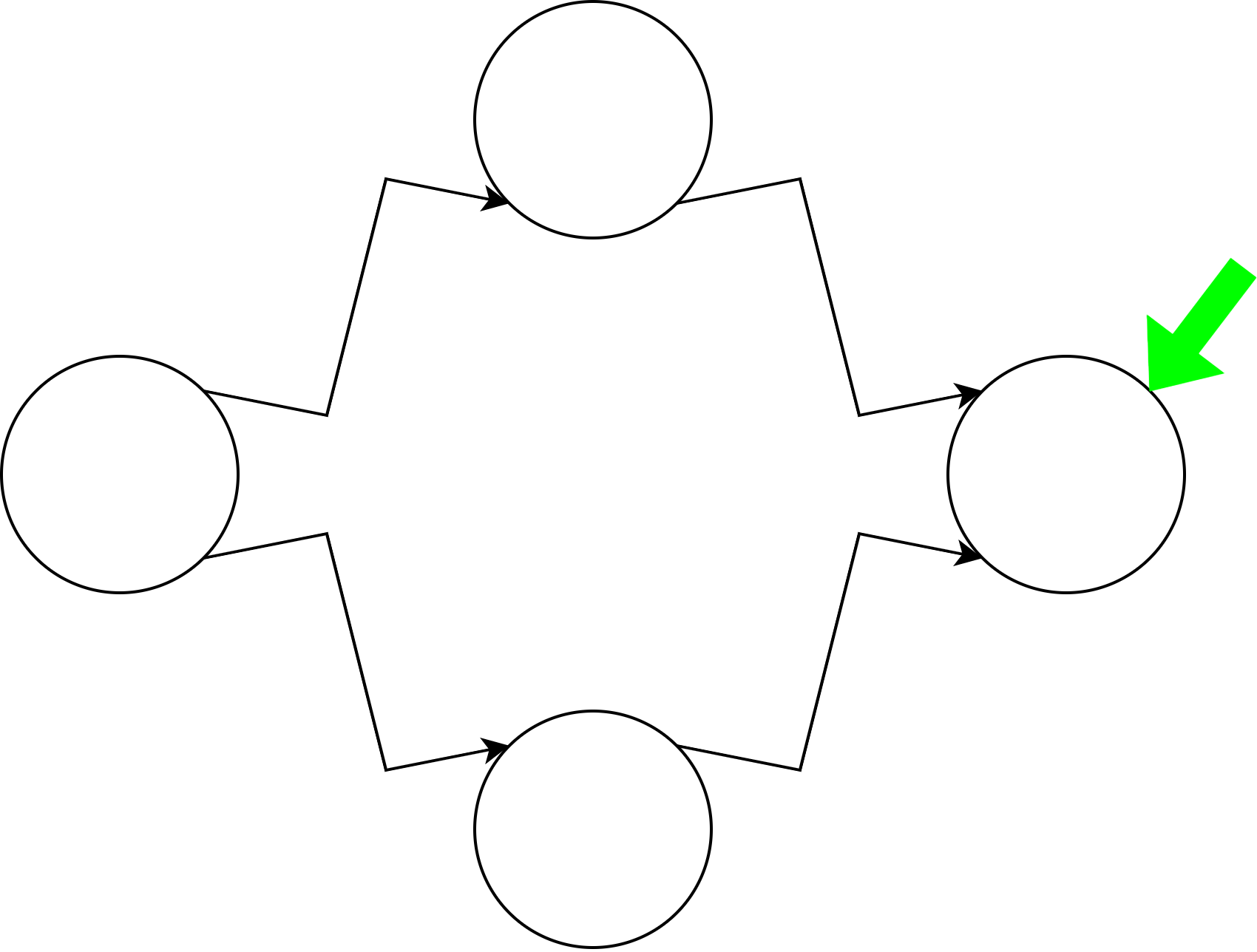
By using this theorem, the time taken for regular expression matching can be made linear to the length of the input string in most cases. Furthermore, since it actually performs backtracking matching, it can mimic the behavior of exact backtracking by recording the number of times a character is read from the confluence until the matching fails, and adding it when it reaches the confluence again.
However, since the implementation of regular expression matching in recheck is based on VM, it should be applied to the confluence of branch instructions, instead of the confluence of branches in the transition diagram.
Notes
- The same acceleration against backreferences can be done by memoizing including the captured positions, but this may actually slow down the matching. Thus,
recheckdoes not perform this acceleration by default when backreferences are included. - At this time, we do not adopt the compression for the memoization data structure in Davis et al.’s research.
References
- [1] Davis, James C., Francisco Servant, and Dongyoon Lee. "Using selective memoization to defeat regular expression denial of service (ReDoS)." 2021 IEEE Symposium on Security and Privacy (SP), Los Alamitos, CA, USA. 2021.