Criteria to Decide Algorithm
Describes the criteria to decide which algorithm is better to use.
Pros and Cons of Each Algorithm
For the algorithm based on automata theory, there are the following pros and cons.
Pros:
- Detection is fast because no actual matching is done.
- Theoretically, accurate detection is possible.
Cons:
- Depending on the regular expression, the size of the equivalent finite state automaton may explode, making detection very slow.
- Not all practical regular expressions can be handled.
On the other hand, for the fuzzing algorithm, there are the following pros and cons.
Pros:
- It can handle all practical regular expressions.
- It is possible to determine vulnerable regular expressions from a practical point of view, as opposed to a theoretical one.
Cons:
- It is possible to erroneously detect a vulnerable regular expression as safe.
- Detection takes some time because the actual matching is done.
Based on these pros and cons, we will consider the criteria for deciding an appropriate algorithm for a given regular expression.
Criteria
If it is likely to be detected correctly by the algorithm based on automata theory, we should use that, otherwise, or if detection is impossible, we should use the fuzzing algorithm.
In practice, as shown in the following flowchart, the algorithm is assumed to be based on automata theory at first and performs NFA conversion, etc., and then falls back to the fuzzing if the size of the NFA exceeds the threshold.
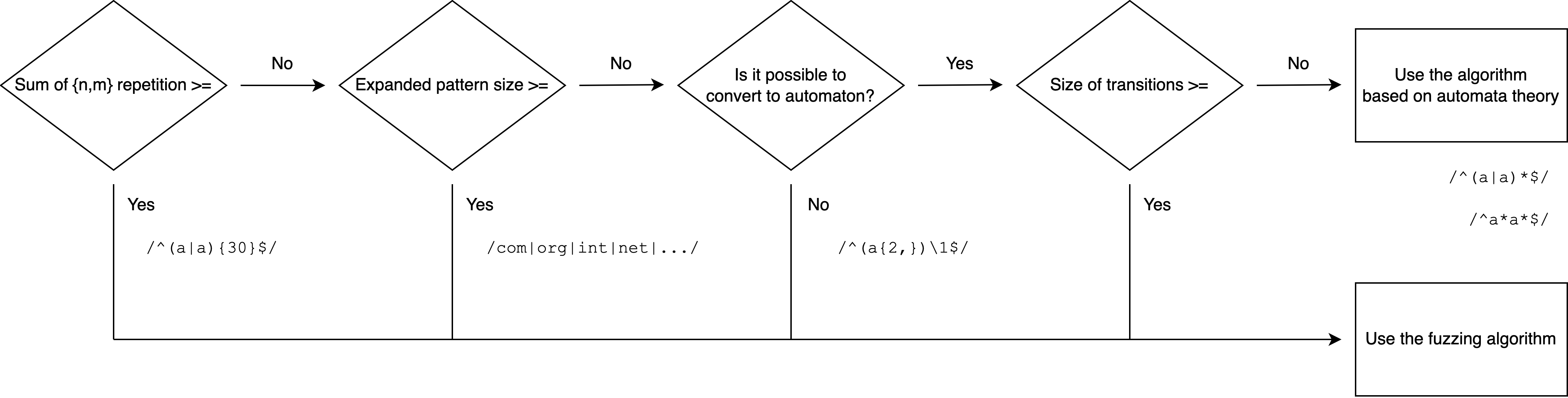
Notes
- The reason why we first determine whether or not to use the fuzzing on a sum of the numbers of quantifiers in the regular expression is to perform ReDoS detection from a practical point of view. For example,
/^(a|a){32}$/is considered safe in theory because it has only a finite number of ambiguities, but in practice, it may try $2^32$ matching processes and is obviously vulnerable.