Fuzzing with Static Analysis
Describes the fuzzing algorithm with static analysis.
Fuzzing
Fuzzing is an automated software testing method that generates a large amount of input called "fuzz" and actually gives it to a program to check if it shows any problematic behavior (i.e. bug). In contrast to static analysis, where the program is not actually run, fuzzing can be considered as a kind of dynamic analysis, where the program is actually run.
One of the features of fuzzing is that evolutionary computation methods such as genetic algorithms are sometimes used to generate fuzz in order to find bugs efficiently.
There is previous research by Shen et al [1]. that used fuzzing to detect ReDoS. In Shen et al.'s research, fuzzing was performed in the following three steps. The implementation of recheck follows the same general flow, but the details are completely different.
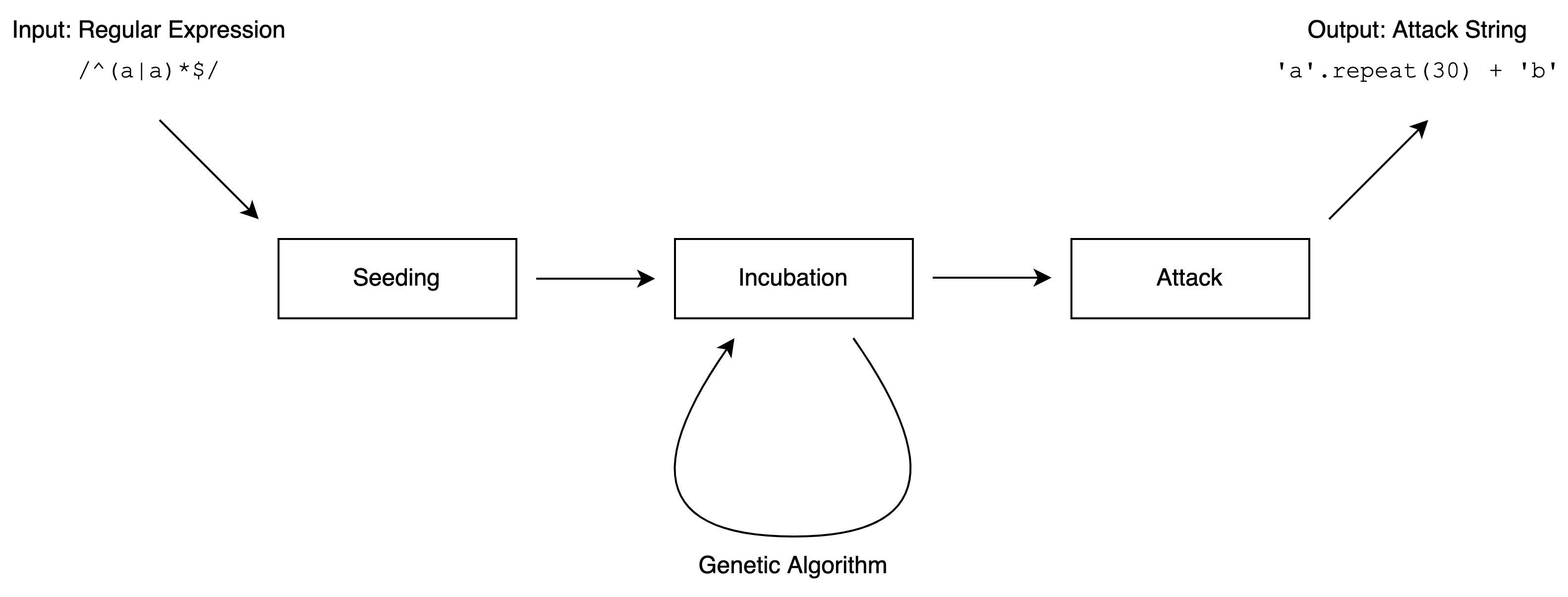
- Seeding is the step where the initial generation of the genetic algorithm is determined from the given regular expression.
- Incubation is the step of iterating through the generations of the genetic algorithm to produce a string that takes more matching time.
- Attack is the step where the strings generated by incubation are used to test whether the matching time is high enough even under conditions close to those of the real attack.
We will now explain each step.
Seeding
Seeding is the step where the given regular expression is statically analyzed to obtain the initial generation of the genetic algorithm.
Let's go back to the previous page and observe the EDA and IDA structures. You will see that the EDA structure and the IDA structure have the following pair of states $(q_1, q_2)$ in common.
- There are two different transitions from $q_1$ with the same letter $a$.
- $q_1$ and $q_2$ can be transitioned with the same letter $b$.
- $q_2$ can transition with the letter $a$.
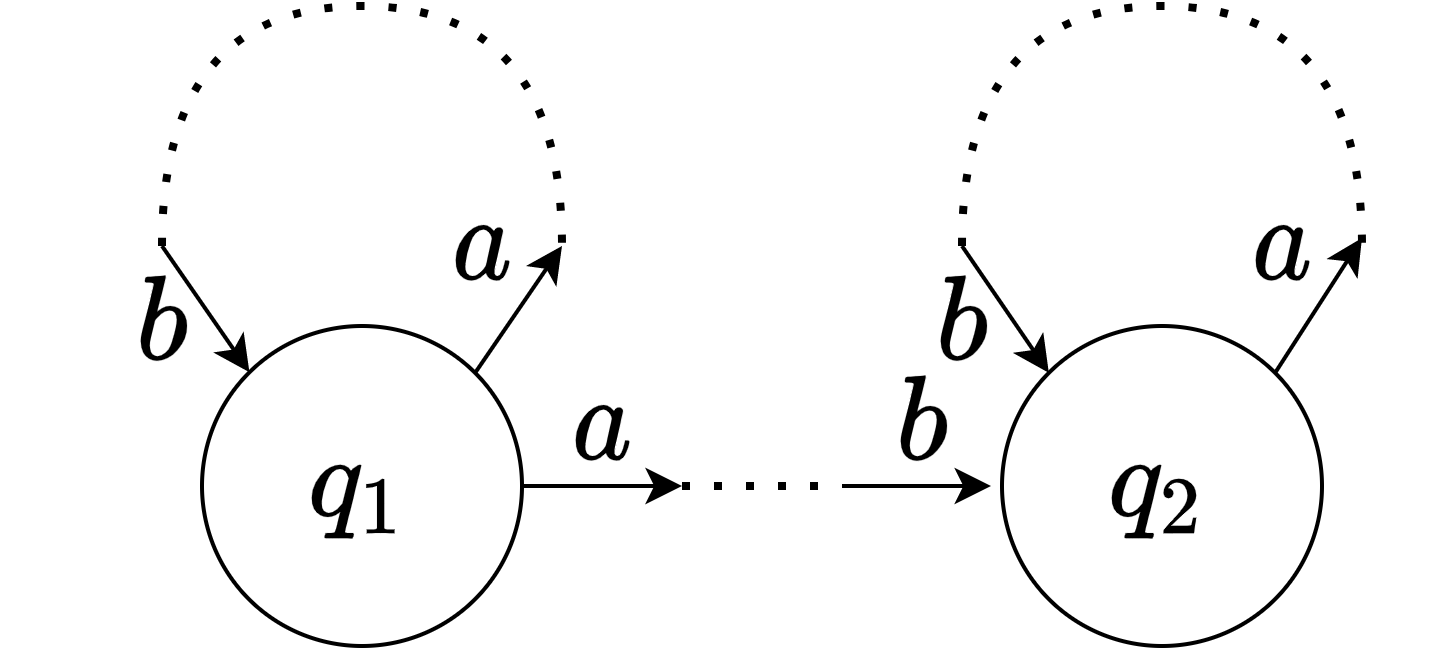
In a way, this pair of states is like a seed of IDA or EDA structure. Adding a repeated string on the string between these two states to the initial generation, we expect the fuzzing to efficiently increase the matching time.
The idea of statically analyzing regular expressions to obtain strings that may cause ReDoS vulnerabilities can be seen in the research of Li et al [2]. However, that work was the syntax direction analysis of regular expressions, and there was a possibility of missing parts of EDA or IDA structures. The observation of state pairs is similar to that of Linear Time Property in Chida et al.'s research [3], but this observation is more detailed.
Seeding with Dynamic Analysis (Legacy)
This section briefly describes seeding using dynamic analysis, which was once used in recheck. This method can also be used by configuration.
In the dynamic analysis, we first input an empty string and record the characters that fail to match. Then, we append the character to the empty string and input it again, and again record the characters that fail to match. By repeating this process of matching and appending failed characters, the strings are collected so that they can be reached everywhere in the regular expression, which is the initial generation of the genetic algorithm.
Incubation
Incubation is the step in which the initial generation obtained by seeding is turned into a string that takes longer to match using a genetic algorithm.
If we find a string that takes enough matching time at this stage, we move on to attack to verify if the string is attackable. In order to acceleration regular expression matching, which will be explained on the next page, the number of times a character is read during the matching is used to determine if the matching takes time or not, rather than the actual matching time.
Then, if no attackable string is found after repeating the generation of the genetic algorithm for the specified number of times, we report that the regular expression is safe.
In recheck, the genetic algorithm uses strings with repetition structures instead of normal strings as genes. A string with repetition structures is a sequence of a normal string $w$ and a string to be repeated $(w)^n$, and the number of repetitions can be changed from outside. This is a genetic programming approach to make a string with structures that can be changed by variables in a gene. In addition, repetition structures are actually encoded in the sequence, which makes mutation and crossover in genetic algorithms efficient.
Attack
Attack is the step to verify whether an attack is actually possible by matching the strings found in incubation while adjusting the number of iterations.
As mentioned above, the genetic algorithm uses strings with repetition structures, and we apply this to determine whether the matching time is exponential or polynomial.
First, assuming that the matching time increases exponentially, we try to match the number of repetitions as the logarithm of the threshold. If the threshold is reached here, then the matching time is exponential. If not, assume that the matching time is polynomially increasing of order $d$ and do the same. Repeating this until $d$ becomes $2$, and if the threshold is not reached until the end, we assume that it is safe for this string and return to incubation.
Notes
- During seeding, some regular expression extensions may appear that cannot be directly converted to NFA (e.g., backreferences). In this case, for example, if it is a backreference, it is necessary to replace it with the regular expression of the referent.
- Seeding is so good that in most cases the attackable string is found before the iteration of the genetic algorithm. However, there are cases where seeding cannot find the attackable string well due to backtracking priorities, etc. In such cases, the genetic algorithm works well.
References
- [1] Shen, Yuju, et al. "ReScue: crafting regular expression DoS attacks." 2018 33rd IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 2018.
- [2] Li, Yeting, et al. "ReDoSHunter: A Combined Static and Dynamic Approach for Regular Expression DoS Detection." 30th USENIX Security Symposium (USENIX Security 21). 2021.
- [3] Chida, Nariyoshi, and Tachio Terauchi. "Automatic repair of vulnerable regular expressions." arXiv preprint arXiv:2010.12450 (2020).